分布・平均・分散
(1)分布
統計の対象とする集団の属性(例えば、身長や体重)を階級に区切って階級別の出現頻度をグラフにしたものが分布図(ヒストグラム)である。データの分布状況を視覚的に把握するのに役立つ。

あらゆる自然・社会現象の背後に母集団分布と呼ばれる確率分布が存在すると仮定する。取りうる値が確率的に決まるような変数のことを確率変数と呼び、確率変数と変数がその値を取る確率との対応を示したものを確率分布という。確率分布は確率(密度)関数によって表され、2項分布など種々の分布の種類がある。正規分布は釣鐘型の左右対称な曲線で示される。
(2)分布の中心
分布の中心についての特性値を代表値といい、最頻値、中央値、平均値がある。正規分布であれば左右対称なのでこれらは一致するが、下の例では一致しない。
現実の統計データでは、正規分布で近似できる場合でも厳密に一致する訳ではないので、データの中心についての情報をこれらのズレから把握することができる。
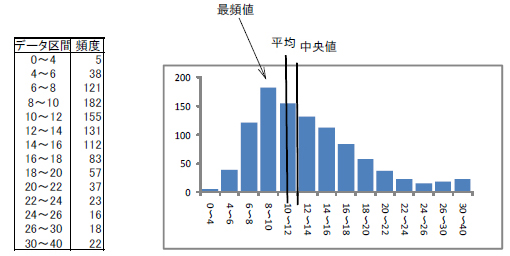
[1] 最頻値(モード mode)
最も頻繁に出現する値を最頻値という。
[2] 中央値(メディアン median)
データを値の昇順に並べたときに中央に位置する値を中央値という。

[3] 平均(算術平均 mean )
平均の概念は、幾何平均などがあり一通りではないが、算術平均が最もよく用いられる。

現実の統計データでは、正規分布で近似できる場合でも厳密に一致する訳ではないので、データの中心についての情報をこれらのズレから把握することができる。
[1] 最頻値(モード mode)
最も頻繁に出現する値を最頻値という。
[2] 中央値(メディアン median)
データを値の昇順に並べたときに中央に位置する値を中央値という。
[3] 平均(算術平均 mean )
平均の概念は、幾何平均などがあり一通りではないが、算術平均が最もよく用いられる。
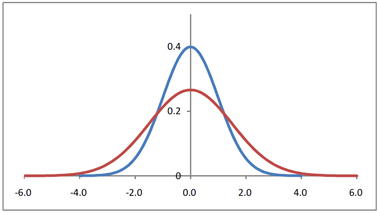
(3)分布のばらつき
平均とばらつきによって分布の形が異なる。ばらつきを捉える特性値として、分散と標準偏差がある。このほかに実用上便利な四分位範囲がある。



[1] 分散(variance)
分散は、個々のデータと平均値の差の2乗和の平均をとったものである。ばらつきは差の絶対値でも表せるが、2乗和の方が数学的に扱いやすいのでこのように定義される。
標本分散は、除数を(n-1)とすると、母集団の分散の不偏推定量となる。母分散の不偏推定量を求めようとするとき、母平均に替えてデータの平均を用いるのでデータの自由度を1下げた除数を用いる。標本(不偏)分散は、 で表す。
で表す。
自由度は、自由に動ける変数の数を意味する。
.jpg) なので、n番目の偏差は他の(n-1)個の変数で定まる。
なので、n番目の偏差は他の(n-1)個の変数で定まる。
[2] 標準偏差(standard deviation)
標準偏差は、分散の平方根である。元のデータと同じ単位に揃っている。
[3] 四分位(quartile)
データを昇順に並べ、データ数を4分の1ずつに分けたとき、第1四分位数Q1 、第3四分位数Q3 が定まる。Q3 -Q1 を四分位数範囲という。
分散や標準偏差は、個々のデータと平均との差から構成するので、突出して大きな外れ値があった場合この影響が強く出るが、四分位数範囲は、外れ値や極端に広い裾野の影響を受けにくい。これを頑健という。
(4)重み付き平均(加重平均)
データに重み(ウェイト)を付けた平均を加重平均という。

度数分布で度数を重み、データを階級の代表値で表すと、加重平均とみることができる。次の例では、平均データに重み(人数)を掛けて重みの合計で割ることが加重平均である。

度数分布で度数を重み、データを階級の代表値で表すと、加重平均とみることができる。次の例では、平均データに重み(人数)を掛けて重みの合計で割ることが加重平均である。
(5)変動係数(coefficient of variation)
変動係数は、標準偏差を平均値で割った量で、平均値の影響を除いたばらつきの尺度である。無次元量で対象物の測定単位の影響がなく、違う単位のものの分布の違いを比べたりする時に便利である。時系列データを比較することもできる。

一人当たり県民所得の変動係数は、全県平均に対する都道府県の開差率を相対的に表したものであり、開差の時系列比較ができる。
